Can We Identify Loyalty Fraud with the Use of Machine Learning?
- Published
- 6 min reading

Large-scale loyalty platforms process millions of transactions originating from hundreds of locations while managing thousands of member accounts at any given moment. Detecting fraudulent activity at this volume and velocity of data processing poses a challenge that can be extremely complicated or even impossible to tackle using conventional methods. Fortunately for program owners, if used effectively, machine learning (ML)/artificial intelligence (AI) solutions may provide exactly the kind of leverage that can help them protect themselves against potential financial and reputational losses resulting from exploitation of their business-critical loyalty system.
First, it is important to emphasize that none of the techniques described in this paper are universal solutions preventing loyalty fraud. Loyalty programs are diverse, depending on the industry, desired business objectives, configuration, and many other factors. What is more, no machine learning system can fully replace traditional fraud protection measures such as the configuration of accrual and redemption limits, control over the number of enrollments, data verification, monitoring the number of risk-prone transactions, or use of a de-duplication mechanism. ML/AI solutions can serve as highly effective enhancements to existing fraud prevention measures, but should by no means be considered their replacement.
What is loyalty fraud?
Loyalty fraud is tricky to define. It is also challenging to try to come up with a short definition that could later be easily translated into an algorithm used by various automated mechanisms. By and large, the name refers to taking advantage of some type of technical or configuration loophole that violates the terms and conditions of a given program. Most of the time, these actions lead to disproportions in a member’s spending or reward activity. Assuming that the vast majority of program members obey the terms and conditions, any fraudulent activity is identified as an anomaly in the full spectrum of legitimate loyalty transactions. Actually, this is one of the well-proven use cases of ML/AI solutions - detecting anomalies in huge and diverse datasets.
Generally, ML solutions can be divided into two main categories: supervised and unsupervised.
- A supervised ML solution is a system that is designed to recognize labeled data on transactions, accounts or other activities, explicitly marked as fraudulent. As a result, the ML-based classifier can select specific data features and compare new transactions with those previously labeled as fraudulent and determine how similar they are in order to identify and report any fraud.
- Unsupervised learning refers to a situation in which the ML system receives no explicit labeling and attempts to detect patterns and connections within the data. While having a data source with labeled fraud instances would be very helpful, at Comarch, we focus on the unsupervised techniques as we believe that they can be adapted to a wider range of implementations.
Although the business goals and objectives of loyalty programs vary most of the time, their primary goal is to reward and retain returning customers, raise brand awareness and improve sales results. As long as we adopt a relatively static loyalty program configuration, there should be some patterns of interaction between the program and its members that can be measured, for instance:
- Earn to burn ratio - determining the typical number of accrual transactions before the points are normally redeemed by a majority of members
- Accumulation speed - learning how quickly point balances grow
- The typical frequency of accrual and redemption transactions
- The typical account lifetime
- The value of distribution for purchases and point operations
- Determining whether there is a relationship between the time since enrollment and the total number of interactions
Machine learning systems are capable of recognizing these and similar types of patterns within the transactional data, and then detecting accounts or individual transactions that do not match the identified model.
Using machine learning in loyalty programs
The majority of loyalty programs are configured to provide customers with a number of loyalty points that corresponds to the value of a given sale transaction. The relationship between one’s total expenditure and the total number of points accrued is typically close to being linear with the majority of program configurations, as exemplified in the diagram below.
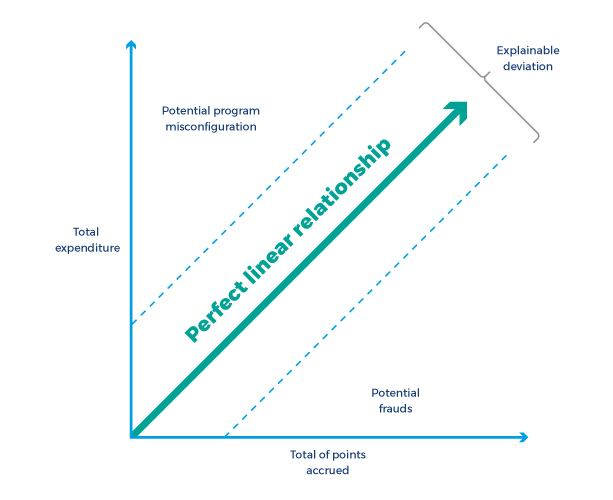
If we were to analyze a very basic loyalty program configuration, for example, where one point is awarded for every $1 spent, we would expect a perfect linear relationship between a member’s total expenditure and the sum of points accrued. The reality is that such programs rarely exist, and program owners usually configure additional promotions, special offers, limited deals, bonus points, etc. Therefore, there is a need to consider a tolerance buffer based on the business knowledge of what should be the maximum explainable deviation from the perfect linear ratio to allow for such activities. If we monitored these metrics constantly and some member accounts appeared as outliers, it could mean that:
- The program was configured incorrectly - a member with a high total expenditure has been awarded fewer points than other members who have spent a similar amount of money
- There has been some fraudulent activity on a given account - if the total number of points accrued is disproportionately higher when compared to total expenditure
Both of the described cases are worth investigating.
As part of the R&D team at Comarch Loyalty Management, we have decided to take a closer look at how we can use machine learning to detect anomalies and fraud.
The main ML technique we analyzed was the use of autoencoders - a type of artificial neural network trained to compress and reconstruct the input, as illustrated in the diagram below.
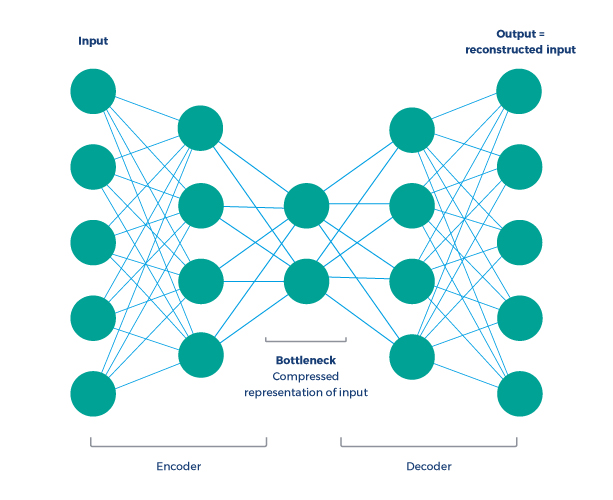
In order to determine the performance of the algorithm and its overall appropriateness for a given purpose, the reconstructed output is compared with the original input. The worse the autoencoder reconstruction, the more likely that an instance is an anomaly. In our case, we have used real-life loyalty program data about member-program interactions and their point balances. As a result, we were able to identify accounts that showed odd earn to burn ratio, quick point gains and losses, significant manual point corrections, repeated transactions, and other unusual patterns. All of the anomalies we detected would be very difficult to identify otherwise. We also carried out several tests with classification trees and clustering algorithms, but autoencoders seem to be the most effective so far.
To sum up, our work so far has proven that machine learning solutions can most definitely provide an advantage in attempts to prevent and detect fraudulent activity within loyalty programs. The remaining challenge is to include those in our loyalty platform and make them reliably capable of processing huge volumes of transactions in real time. The overarching goal is to make the entire loyalty experience more secure, and this is also why we think it is worth the effort.



